某个清晨,美国北加州地区的民众一觉醒来,发现野火浓烟后的西海岸上空一片橙红。这种像是从《银翼杀手》电影中走出来的景象,很多人在现实生活中可能从未见过。

到底发生了什么?
自然而然地,就像国内大多数网民会打开百度甚至知乎搜索答案一样,一时间加州人民也纷纷潮涌至 Google,键入了类似「为什么天空是橙色的」这样的搜索关键字 —— 这些在搜索引擎眼里或许有点无厘头的问题,依然通过信息卡片、精选新闻资讯的方式得到了精准而及时的解答。
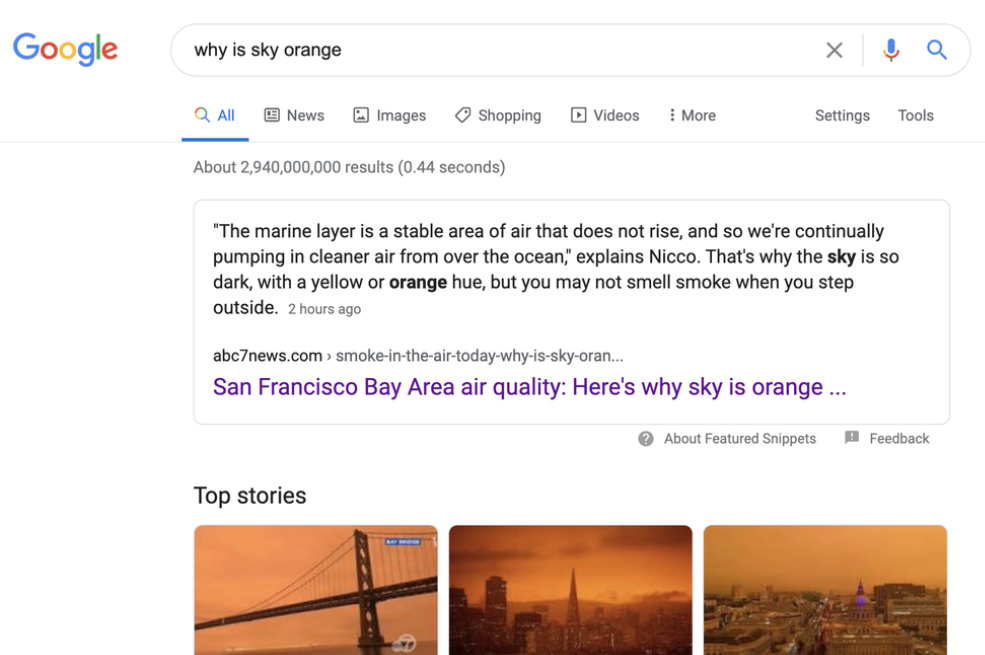
以上是 Google 不久前分享的一个案例。当我们将 Google 搜索引擎从上面这个事件中剥离出来仔细审视时,不少人应该都会心生疑窦:Google 是如何知道用户要搜什么的,为什么针对加州地区的当地资讯会排在页面顶部,其它地区的人搜索同样的问题会得到类似的答案吗,结果页面左侧的知识面板在这样的搜索中发挥了怎样的作用……
为了让你多了解一点这个世界上最受欢迎的搜索引擎,Google自 2018 年以来就开始陆续在 The Keyword 博客中分享关于 Google 搜索引擎的各种细节与原理。如果你也有上面这些疑问,不妨跟随本文一起探究 Google 搜索引擎背后的秘密。
搜索建议是怎么「蹦」出来的?
每天我们都要和搜索引擎打交道,而每次使用 Google 搜索信息时,键入搜索关键字的同时搜索框下方都会不断「蹦」出各种各样根据已输入词汇扩展而来的搜索建议。是此时的 Google「能掐会算」,早就知道了你心里的那点小心思吗?
这种「能掐会算」的背后是 Google 的一项名为自动填充(auto complete)的技术。从我们录入开始,Google 就开始在搜索框的下方显示它所猜测的搜索关键字结果。只要有任意一条「猜测」命中,我们就能快速完成输入。
这种「猜测」(官方称为「预测」)其实是系统在不断使用我们键入的词汇进行联想查询,我们不断输入的同时,搜索框下方提示的文字内容也会根据「猜测」结果不断调整。这其实也是为什么网络环境不太好的时候搜索建议可能会表现得反应迟滞甚至完全不会「蹦」出搜索建议的原因。
为了提高这些搜索建议的命中率,Google 还会进一步引入相关因素来进行预测校准,进行搜索的用户所处的地理位置、当下的热门甚至用户所使用的设备……这些都会对自动填充生成的搜索建议产生影响 —— 当然了,很多人应该也知道,我们在 Google 上保存的搜索历史和各种搜索设置同样也会影响到具体的预测结果。
搜索设置会影响搜索结果,但只是众多影响因素的一部分
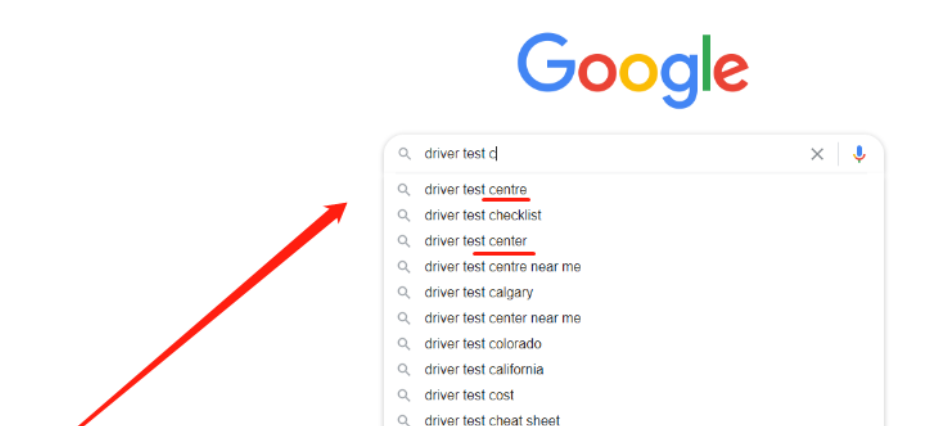
举个例子,在 Google 搜索引擎使用率更高的欧美地区,Google 往往会根据搜索用户所处的地理位置预判他们使用的是英式英语还是美式英语,进而提供差异化的内容显示 —— 在英式英语的语境下「football」通常会是足球,而在美式英语下往往是橄榄球,Google 也会这么做;与之对应的,Google 还会在单词拼写上进行建议,比如根据搜索者的所在地区对「center」和「centre」的写法进行区分。
注意观察图中位置与单词的拼写
由此其实也可以得出一个事实:每个人在 Google 中进行的每一次搜索都是高度个性化的,即便我们使用浏览器的隐私浏览模式排除个人搜索和浏览记录的干扰,实际搜索结果还是会根据其它因素进行调整。
精选摘要:不用翻查、即问即答
我只是要找个答案而已,并不想点开网页。
经常使用搜索引擎获取信息的人一定会有类似的想法,让他们养成这个习惯的原因之一,很有可能就是 Google 经常会在搜索结果页面上方直接生成的那个信息卡片 —— 直接、干脆,你问、它答。
这个答案是怎么来的?
首先,这个卡片也有一个特定的名字:精选摘要(featured snippets),套用一句俗话,「生活就像水中的鸭子,表面上从容淡定,其实水底下在拼命划水」。精选摘要的来源也是这样 —— 在我们键入、搜索的过程中,Google 表面上只是从容淡定地搜索、跳转,背后的零点几秒时间里,幕后其实也在「拼命划水」。搜索系统算法会根据我们所搜索的问题检索一些相对具备权威性的高质量网站页面,然后从这些网站中提取关键内容来生成摘要,最后把这份摘要呈送到我们眼前,即上面所说的「精选摘要」。
然而算法毕竟是算法,也会有阴沟翻船的时候,其中最著名的例子莫过于「古罗马人夜间如何计时」这个问题,最初 Google 给出的答案是:
日晷。罗马人最初使用日晷来测量时间流逝。通过这种方法他们不仅可以相对准确地获取日出、日落和正午时间,还能根据日影长度估算一天中的其它时刻。日晷这种新工具的引入给了罗马人一种更好的测量时间的方法……
那么夜间没有太阳如何用日晷计时呢?Google 的精选摘要那时也不知道。是不是有点你学生时代答非所问但一定要把试题纸写满的味道了……
知识图谱:强力的信息补充
上面我们已经了解了「精选摘要」,也见识了它的「胡说八道」,那当我们意识到精选摘要似乎在「乱侃」的时候怎么办?或者这个搜索页面根本就没有精选摘要……
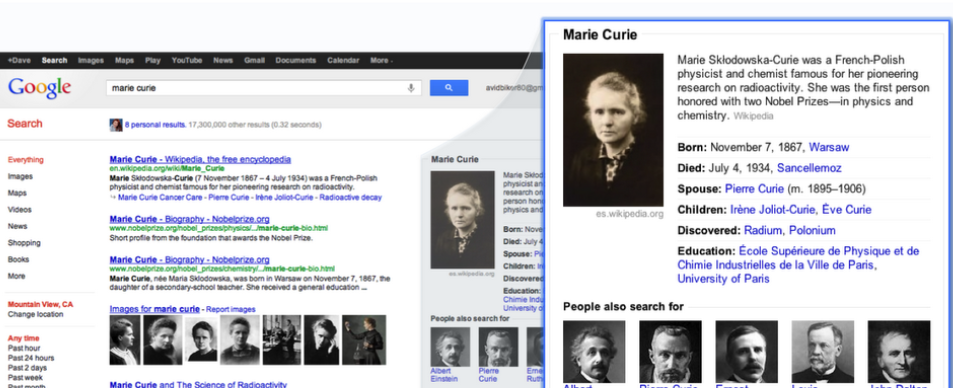
你可能已经有这个习惯了:向右看。页面右侧可能会出现一个知识面板,它包含了当前搜索话题相关的知识信息,没准也能在你的搜索中派上用场。这个知识面板(Knowledge Panel)与早年 Google 精心搭建的知识图谱(Knowledge Graph)体系密切相关。
简单来说,知识图谱是一个由各种不同页面、不同来源的信息构成的小「知识库」,根据话题的不同,Google 通过语义算法自动整理、归纳不同内容的相关信息,这些信息同时会随着原始来源页面的变化而自动更新。
因此当我们在搜索人物、地点、组织等信息的时候,知识面板可以直接将相关内容汇总为一张知识面板放在搜索页面右侧。目前这个面板中所收纳的内容已经相当丰富了,以 Apple 的知识面板为例,我们可以直接在知识面板中找到 Apple 这家公司的基本信息介绍、股价信息、业务范围、售后电话、社交账户页面、热门产品甚至换电池业务页面……比起跳转到某个互联网犄角旮旯里才能找到官网的体验来说这样的知识面板能够大幅提高话题信息的检索效率。
尽管知识面板偏居一隅,但是 Google 对它还挺上心的。按照 Google 的说法,截至 2020 年 5 月,知识面板已经收集了约 50 亿个实体、超过 5000 亿个名词实例,说它是一本藏在 Google 搜索引擎里的「百科全书」不过分吧?
哪些结果排前面?不是钱说了算
精选摘要也好,知识面板也罢,这些都可以简单归纳到快速答案范畴内。假如把整个搜索过程比作是一顿饱餐,精选摘要、知识面板只不过是餐前甜点,页面主体内容里的搜索结果才是正餐。
所以很多人在浏览 Google 搜索结果的时候,随着鼠标的滚轮不断滑动、蓝色的搜索链接飞速掠过,很自然地就会有一个不成熟的小想法:这么多的搜索结果是如何排序的,前面这几个会不会跟某些搜索引擎一样是收了钱的?
「犯罪嫌疑人」是这样说的
这个问题就涉及到了搜索排名算法了。
这里最为大众所熟知的搜索排名算法应该就是 PageRank 了。这也是 Google 最早使用的 对网页进行的排名算法。对,就是你的潜意识里的那个名字,拉里·佩奇(Larry Page),这个算法正是用 Google 创始人(之一)的名字命名。
虽然 Google 主要靠广告挣钱,影响搜索结果排名的主要还是算法本身,但金无足赤,算法同样也有问题。PageRank 的缺陷就包括「旧的页面的排名往往会比新页面高」,也同样因此成为了一些人「刷排名」的漏洞。因此 Google 在 2016 年 关闭了 PageRank 数据开放的大门。
诚所谓条条大路通罗马,尽管时间在变、算法在变,不过 Google 表示保证搜索结果排名质量的初心并没有变。按照 Google 的说法,目前 Google 搜索引擎的排名系统是以质量为导向的,它由一系列算法组成,在搜索过程中,我们搜索的字词、搜索目标网页的相关性、可用性、来源专业程度等等都会影响到算法和页面的最终排名。用户搜索话题的性质不同也会影响页面的内容排序。
所以从某种程度上来说,Google 搜索引擎现阶段的排名算法其实是有点「黑盒子」,它不像早年 PageRank 那样公开透明,但依然维持着较高的搜索结果排名质量 —— 当然,Google 用来「养家糊口」的广告往往还是会排在搜索结果的上面,好在它们和少数派网站一样都标注得蛮清楚。
用人力保证搜索结果质量
没错,讲了这么多预测、知识图谱与算法,保证 Google 搜索结果质量最后一环的竟然还是人。
就像上面提到的那个「罗马人夜间用日晷计时」的笑话一样,搜索结果词不达意甚至答非所问的情况是有的,而算法很难自查。为了减少类似的情况发生,Google 充分调动这样几波人的智慧:
专家、权威机构。在搜索健康财务、公民信息( civic-information )和危机情况等话题的时候,我们能直接在搜索结果中优先看到来自当地政府、卫健、选举等权威机构的信息。这样我们就能从源头上得到靠谱的信息。
Google 内部团队。这当中不得不提到的有两支团队:一支是专门的研究团队,一支是内容合规团队(enforcement team)。前者通过对世界各地的具体情况进行「实地考察」来改进个性化搜索质量;后者依照 Google 的政策处理那些系统没有拦住的违规内容。
搜索质量评分员(Search Quality Rater)。他们是对搜索质量进行 E-A-T 评级的人,E-A-T 评级反映了搜索结果的专业性(Expertise)、权威性(Authoritativeness)和可信度(Trustworthiness);评分员同时也是帮助 Google 评估我们在搜索行为上实际体验的人。根据 Google 的数据,目前参与这些工作的评分员有 10000 多人。
P.S. 评分员在开始提供评级服务之前,需要学习 Google 发布的《搜索质量评分者指南》并且通过相应考试。整个评估工作也要遵照该《指南》进行。
除了以人之智慧补算法之不足之外,Google 同样没有放弃对算法优化的努力。以「网页的相关性和可用性」而言,Google 拥有多种语言理解系统。这些语言理解系统中既有对应拼写错误、同义词等内容系统,又有基于 AI 的系统。通过这些系统,Google 得以了解与我们搜索最相关的结果并进行改善。
配合人为主导的并行实验、实时流量实验等一系列的工作,最终 Google 得以保证我们在 Google 搜索引擎中的实际体验。根据 Google 披露的数据,2019 年他们与搜索质量评分者一共进行了 383605 余次搜索质量测试、62937 次并行实验、17523 次实时流量实验,这些努力帮助 Google 对搜索算法进行了 3600 多次改进。
修正前与修正后的精选摘要答案对比
小结
一次简单的搜索行为、一个稀松平常的搜索结果页面,背后的算法、原理、构成和人力因素其实都复杂且精妙。
太阳每天都是新的、互联网发展不断向前,我们的搜索需求也水涨船高,回首来路,也正是因为 Google 在「搜索」这件事情上的不断改进和优化,才让它最终成为了不少人心中那个最靠谱的首选。