对于想入局小红书、产出爆款笔记的博主们而言,有哪些规则是需要注意的?与此同时,博主们又可以采取怎样的运营策略,产出爆款笔记,实现快速增粉?本篇文章里,作者便结合自身经验,对小红书的运营策略进行了解读,一起来看。

Hi,小伙伴,见字如面。
分享自己对于小红书的一些理解,主题是《爆款内容的诞生与极致利用》。
一、小红书流量机制解析
小红书对于笔记流量来源有 2 种略有不同的划分。

1 种是小红书创作中心对于笔记流量来源的划分:
- 首页推荐;
- 搜索;
- 关注页面;
- 个人主页;
- 搜索;
- 其他来源。
另 1 种是小红书蒲公英对于笔记流量来源的划分:
- 发现页;
- 搜索页;
- 关注页;
- 博主个人页;
- 附近页;
- 其他。
这 2 种划分实际上差不多,但是小红书近期有一些调整,所以上述的划分并没有及时更新,因此小红书现在的笔记流量来源有这些:
- 发现页;
- 关注页;
- 视频流;
- 搜索页;
- 个人主页;
- 小红书群聊;
- 其他。
而小红书的笔记流量来源主要取决于推荐与搜索。
1. 推荐系统基本链路

用户刷新小红书后,推荐系统会同时调用几十条召回通道,每条召回通道从数据库里快速取回几十到几百篇笔记,一共取回几千篇笔记,这些召回通道实际上就是不同的算法/规则在作用,从数据库里进行去重、过滤、筛选。
然后用规模比较小的机器学习模型,给几千篇笔记逐一打分,按照分数做排序和截断,保留分数最高的几百篇笔记,即粗排与截断。
之后用大规模的深度神经网络给几百篇笔记逐一打分,即精排。
粗排与精排的原理基本相同,实际上就是用不同深度的机器学习模型及神经网络等,预估用户对于笔记的兴趣,根据预估的兴趣分数进行排序。
几百篇笔记带着精排分数进入重排,重排会考虑内容多样性问题,根据精排分数和多样性分数做随机抽样,得到几十篇笔记,再把相似的笔记打散,避免把过于相似的内容排在相邻的位置上,最后插入广告和运营内容,以及根据生态要求调整排序呈现给用户。
1)召回通道

推荐系统在推荐分发过程里所调用的召回通道实际上就是不同的算法/规则在作用,从数据库里进行去重、过滤、筛选,所以阐述一下几条比较重要/常用的召回通道。
① 基于物品的协同过滤
在小红书推荐系统里,物品即内容,所以基于物品的协同过滤即基于内容的协同过滤。
基于内容的协同过滤的基本思想是根据内容的相似度做推荐,因为用户对这篇内容感兴趣,而这篇内容与另一篇内容相似,所以用户也很可能会对另一篇内容感兴趣。
举个例子。
我喜欢看《笑傲江湖》,《笑傲江湖》与《鹿鼎记》相似,但是我没有看过《鹿鼎记》,这个时候推荐系统就会给我推荐《鹿鼎记》,而推荐的理由就是《笑傲江湖》与《鹿鼎记》相似。
至于推荐系统是如何判断《笑傲江湖》与《鹿鼎记》相似的,其实很简单。
比如通过知识图谱,这 2 本书籍的作者相同,所以这 2 本书籍相似;
比如基于所有用户的行为分析,给《笑傲江湖》好评的用户,也给《鹿鼎记》好评,所以这 2 本书籍相似,通过用户的行为挖掘出内容之间的相似性,再利用内容之间的相似性做推荐;
比如基于内容受众的重合度,喜欢看《笑傲江湖》的用户跟喜欢看《鹿鼎记》的用户重合度比较高,所以这 2 本书籍相似……
因为基于内容的协同过滤会基于内容受众重合度进行推荐,但是又希望 2 篇内容重合的受众是广泛且多样,而不是集中在一个小圈子里的,所以基于内容的协同过滤会给用户设置权重,解决小圈子之类的问题。
② 基于用户的协同过滤
基于用户的协同过滤的基本思想是根据用户的相似度做推荐,因为我跟某位用户的兴趣爱好之类相似,所以我感兴趣的内容很可能这位用户也会感兴趣。
举个例子,
我跟某位用户的兴趣爱好之类相似,我对某篇内容感兴趣,但是这位用户没有看过,这个时候推荐系统就会给这位用户推荐我感兴趣的这篇内容,而推荐的理由就是我跟这位用户的兴趣爱好之类相似。
至于推荐系统是如何判断我跟这位用户兴趣爱好之类相似的,其实很简单。
比如通过查看我跟这位用户过往感兴趣内容的重合度,判断我跟这位用户的兴趣爱好之类是否相似;
比如通过查看我跟这位用户的关注列表的重合度,判断我跟这用户的兴趣爱好之类是否相似……
但是在这个判断过程存在一个问题,即不同用户对于同一热门内容/作者感兴趣的概率极大,这样就容易导致错误判断用户的相似度。
举个例子。
《笑傲江湖》是热门内容、周杰伦是热门作者,我喜欢 TA 们,我的长辈也喜欢 TA 们,但是我跟我的长辈兴趣并不相似。
所以为了更好地计算用户相似度,基于用户的协同过滤会降低热门内容/作者等的权重,避免产生误判。
③ 地理位置召回
根据用户所在的地理位置做推荐;只看地理位置,不考虑用户兴趣,基于地理位置、时间顺序、优质内容做推荐。
④ 同城召回
与“地理位置召回”同理,唯一不同的是同城召回是根据用户所在的城市和曾经生活过的城市做推荐。
⑤ 作者召回
根据用户感兴趣的作者做推荐,因为我对某位作者感兴趣,所以这位作者的其他内容我很可能也会感兴趣。
举个例子。
我在小红书上关注了某位作者,但是这位作者最近新发布的内容我没有看过,这个时候推荐系统就会给我推荐这位作者最近新发布的内容。
至于推荐系统是如何判断我对这位作者感兴趣的,其实很简单。
比如通过查看我是否有关注这位作者,判断我对这位作者是否感兴趣;
比如通过查看我是否对这位作者所发布的内容感兴趣, 判断我对这位作者是否感兴趣……
因为用户感兴趣的作者可能比较多,所以作者召回会优先级根据用户最近感兴趣的作者做推荐,而用户之前感兴趣,但是最近没有交互过的作者则不会被推荐。
⑥ 相似作者召回
根据用户感兴趣作者的相似度做推荐,因为这位作者感兴趣,而这位作者与另一位作者相似,所以另一位作者发布的内容很可能用户也会感兴趣。
举个例子。
这位作者跟另一位作者相似,用户对这位作者感兴趣,但是另一位作者发布的内容用户没有看过,这个时候推荐系统就会给用户推荐另一位作者发布的内容,而推荐的理由就是这位作者跟另一位作者相似。
至于推荐系统是如何判断这位作者跟另一位作者相似的,其实很简单。
比如通过查看这位作者跟另一位作者的粉丝重合度,判断这位作者跟另一位作者是否相似……
……
2)预估分数的维度
粗排与精排的原理基本相同,实际上就是用不同深度的机器学习模型及神经网络等,预估用户对于笔记的兴趣,根据预估的兴趣分数进行排序,而排序的主要依据是:
机器学习模型及神经网络等对于内容点击率、点赞率、收藏率、转发率之类的指标做预估,做完预估后,把这些分数按照不同权重比例进行融合,比如行业里经常提及的 CES,CES = 点赞数 * 1 + 收藏数 * 1 + 评论数 * 4 + 转发数 * 4 + 关注数 * 8……最后按照融合的分数给内容做排序和截断,保留分数最高的内容,淘汰分数低的内容。
上述的 CES 是 2017 年提及至今的,所以哪怕是真的,也已经是过去式啦。
因为真实的内容预估及融合分数算法是不可知的黑盒,所以就只能通过知晓预估分数的一些维度,把控好变量来提高预估及融合分数啦。

① 用户画像
- 性别;
- 年龄;
- 用户注册时间;
- 活跃度;
- 新/老用户;
- 高/低活跃用户;
- 感兴趣的类目、关键词、品牌;
- ……
② 内容画像
- 内容 ID;
- 内容发布时间;
- 内容年龄(内容发布时长);
- 定位;
- 标题;
- 类目;
- 关键词;
- 品牌;
- 笔记字数;
- 图片数;
- 视频清晰度;
- 标签数;
- 内容信息量;
- 图片美学;
- ……
内容信息量与图片美学等内容质量维度是小红书算法打的分数,在内容发布的时候,小红书就用模型给内容打分,把内容信息量、图片美学等内容质量维度的各项分数计入内容画像。
但是内容信息量并不一定需要多,而是需要精准直白,可被机器学习模型及神经网络理解,因此会发现有许多爆款内容只是几张图片、几句话,其实就是因为内容信息量不多,且精准直白,机器学习模型及神经网络知道可推荐给谁。
而图片美学是个比较感性、主观的东西,但是会有一些基础标准在,比如真实、整洁、自然等,并不一定需要有多惊艳,关键是不能太凌乱,太做作……
③ 用户统计特征
- 用户最近 30 天 / 7 天 / 1 天 / 1 小时等时间段的点击率、点赞率、收藏率、转发率等;
- ……
④ 内容统计特征
- 内容最近 30 天 / 7 天 / 1 天 / 1 小时等时间段的曝光数、点击数、收藏数等;
- ……
⑤ 作者统计特征
- 发布的笔记数量;
- 粉丝数;
- 消费指标:曝光数;点击数;点赞数;收藏数;……
这些特征反映了作者的受欢迎程度,以及 TA 的作品的平均品质,所以假设一位作者的品质普遍很高,那 TA 新发布的作品大概率也会很高。
⑥ 场景特征
- 用户当前的定位;
- 用户当前定位的城市;
- 当前的时刻;
- 设备信息;
- ……
2)新笔记的推荐全链路

① 机器/人工审核
笔记发布后,小红书会对笔记内容进行机器/人工审核。
一般是机器先审,假设机器判定为疑似违规或者不可判定的情况下,会交由人工进行审核。
审核主要是围绕小红书的相关规则规范,以及一些隐性规则等进行审核。
假设笔记涉嫌违规,小红书会根据违规程度进行不同程度的惩罚,轻则限流,重则完全屏蔽。
- 轻度限流:减少流量推荐。
- 重度限流:没有推荐与搜索流量,仅有私域性质流量,即仅推荐分发给粉丝,在小红书群聊、个人主页等私域性质界面均可查看。
- 完全屏蔽:没有任何流量,笔记不可查看,即除自己以外所有账号/方式均没办法查看。
② 打标签与打分
笔记在审核的同时,小红书会对笔记进行打标签与打分,实际上就是用机器学习模型及神经网络等,识别笔记内容进行内容质量打分,以及预估用户对于笔记的兴趣分数,因为是新笔记,所以小红书仅能从这些维度去预估分数:
a. 内容画像
- 内容 ID;
- 内容发布时间;
- 定位;
- 标题;
- 类目;
- 关键词;
- 品牌;
- 笔记字数;
- 图片数;
- 视频清晰度;
- 标签数;
- 内容信息量;
- 图片美学;
- ……
b. 作者统计特征
- 发布的笔记数量;
- 粉丝数;
- 消费指标:曝光数;点击数;点赞数;收藏数;……
③ 实时推荐
新笔记的推荐链路跟上述“小红书推荐系统的链路”基本一致,但因为是新笔记,所以笔记缺少信息,需要精准推荐。
所以小红书会把流量向新笔记倾斜,让新笔记获得更多的曝光机会,进而激励作者的发布积极性。
因此,小红书会在推荐新笔记的时候,会针对新笔记做推荐全链路优化,包括召回和排序,让新笔记有足够的机会走完链路被曝光,且会尽量让新笔记的推荐做得准,不引起用户反感。
小红书会在推荐新笔记的时候,给新笔记增加单独的召回通道,比如:
根据类目/关键词,按照发布时间倒排,最新发布的笔记排在最前面做推荐。
聚类召回:基于笔记的图文内容做推荐,假设用户对一篇笔记感兴趣,大概率会对内容相似的笔记感兴趣。
……
小红书会在推荐新笔记的时候,给新笔记在排序阶段提权,根据新笔记的内容质量、作者质量,给新笔记单独定一个曝光保量目标,达到曝光保量目标之后,就会停止扶持,让新笔记自然分发,跟老笔记公平竞争。

这也是为什么有些博主会感觉自己的笔记发布 1-2 小时数据好,但是 1-2 小时之后,数据突然变差了,实际就是因为在刚发布的时候,笔记有差异化提权保量,但是笔记在达到曝光保量目标之后,就会停止扶持,让新笔记自然分发,跟老笔记公平竞争,所以流量增长速度变慢啦。
3)小红书搜索引擎的链路

小红书搜索引擎的链路主要是 3 个关键环节,查询词处理、召回、排序。
用户在小红书搜索框输入想搜索的内容后,搜索引擎会对用户输入的查询词(想搜索的内容)进行处理,主要是分词与理解。
在处理的同时,搜索引擎会调用一些召回通道,从数据库里快速取回几十到几百篇笔记,一共取回几千篇笔记,这些召回通道实际上就是不同的算法/规则在作用,从数据库里进行去重、过滤、筛选。
取回后,搜索引擎会根据对于查询词的理解、相关性、内容质量、时效性、个性化等进行排序,再把相似的笔记打散,避免把过于相似的内容排在相邻的位置上,最后插入广告和运营内容,以及根据生态要求调整排序呈现给用户。
① 查询词处理
用户在小红书搜索框里输入想搜索的内容后,搜索引擎就会对用户所输入的查询词(即用户在小红书搜索框输入想搜索的内容)进行处理。
- 分词;
- 拼写纠错;
- 同义词改写;
- 针对所分解的词进行打分,形成不同权重的关键词;核心词:核心意图,去掉之后意思完全改变,没办法搜索到用户想要的结果;重要词:核心意图的重要组成部分,去掉之后意思有所改变,但是依然可搜索到用户想要的结果;辅助词:修饰意图,去掉后意思变化比较小,对于搜索结果影响不大,但是有利于个性化推荐。

举个例子。
用户输入的查询词是“日系中长发男生造型”,所以:
核心词:男生造型;
重要词:中长发;
辅助词:日系;
所以,在选择关键词的时候,可基于查询词处理的逻辑,把搜索热词进行分词,侧重植入核心词与重要词,以此提高笔记搜索排名。
② 召回
跟推荐系统的召回类似,搜索引擎会根据对于查询词的理解调用召回通道,从数据库里快速取回几千篇笔记,所以阐述一下搜索引擎召回通道的一些关键性原则。

搜索引擎的召回通道会基于对查询词的理解及用户的个性化做推荐,即把对于查询词的理解与数据库的笔记做匹配,笔记匹配上的关键词越多越好,匹配上核心词加分多,匹配上辅助词加分少。
所以一个关键词在一篇笔记里出现 3 次比在一篇笔记里出现 1 次好。
所以匹配上核心词比匹配上辅助词。
即把用户特征等与数据库的笔记做匹配,笔记所预估的用户兴趣度越高越好。
③ 排序
跟推荐系统的排序类似,搜索引擎会用机器学习模型及神经网络等,预估内容跟对查询词理解及用户兴趣等的融合分数,根据分数做截断与排序,再插入广告和运营内容,以及根据生态要求调整排序呈现给用户,所以阐述一下搜索引擎打分排序的一些关键性维度。

a. 相关性
根据对于查询词的理解,预估内容跟对于查询词的理解的相关性分数。
b. 内容质量
作者 EAT:
- 专业性:作者是否有专业资质;
- 权威性:作者在领域里的影响力;
- 可信赖性:名声好坏、是否有广告,包括软广。
笔记意图:
- 有益:分享有用的攻略、知识、信息;
- 有害:传播虚假信息、散播仇恨。
没有特别的意图:
内容质量分;
内容价值分;
点击数、交互率等业务指标是否达到 Top 10%。
c. 时效性
- 基于对查询词的理解,判断是否有时效性诉求;
- 内容发布时间比较久远,是否还有价值;
- 发布时间。
d. 个性化
类似于推荐系统的个性化推荐,但是没有推荐系统的个性化推荐强,预估维度、方式等跟推荐系统类似。
通过这些维度:
- 查询词特征;
- 笔记特征;
- 用户特征;
- 统计特征;
- 相关性特征。
预估用户对于笔记的兴趣度:
综上,笔记互动数据高,并不一定代表笔记会出现在搜索前排,出现在搜索前排的笔记是实际上融合等分数高。
4)其他
① 补充概述
小红书的推荐与搜索各自独立,但又藕断丝连。
- 各自独立:推荐与搜索互不干扰,所以小红书笔记的收录与否并不影响推荐;
- 藕断丝连:笔记在获得搜索流量后,一定程度上会影响笔记推荐流量。
小红书笔记流量激增大概率会触发小红书二次审核,而二次审核大概率会是机器+人工一起审核;
所以有些笔记在流量激增后被突然限流、掉收录等,或许是因为二次审核,以及系统对于笔记的实时预估变化的缘故。
正确判断笔记是否被收录的方式并不是搜索标题等,而是在创作中心/蒲公英平台查看笔记是否有搜索流量,有搜索流量即代表笔记被收录。
假设对于推荐、搜索机制比较感兴趣,想深入学习的话,可看看这些内容。
② 推荐系统公开课
基于小红书的场景讲解工业界真实的推荐系统
链接 🔗 https://space.bilibili.com/1369507485/channel/collectiondetail?sid=615109
作者:王树森
小红书搜推算法工程师、基础模型团队负责人
③ 书籍推荐
- 《智能搜索和推荐系统》;
- 《推荐系统实践》;
- 《SEO 实战密码》;
③ 公众号推荐
小红书技术 REDtech
5)写在最后
真实的系统/算法是黑盒,但是我们需要理解系统/算法的基本原理/底层逻辑。
二、不同逻辑下的爆款内容生产
1. 用内容投喂算法
用垂直内容投喂算法建立定向标签,通过简单、直接、可复制、可批量化生产的内容去获取精准流量,虽然流量不会太大,但是比较精准。

内容不需要太复杂、太精美,需要的是简单、直接、可复制、可批量化生产,因为这样可极大程度降低内容创作成本,以及让算法理解到位,之所以会有许多简单的爆款内容出现,实际上就是简单的内容有利于算法推荐。
2. 用确定性蒙骗算法
对于爆款内容的模仿、复刻等,实际上就是利用爆款内容的确定性去蒙骗算法,让算法觉得内容质量、价值高。

但是在模仿、复刻的时候,就需要针对爆款内容进行剖析,哪些是爆款因素,哪些是无关紧要的因素,假设做不到比较好的剖析,那就 100% 复刻,包括场景、构图、产品等,把变量控制到最小,但是需要有一些无关紧要的变量来提高原创度。
举个例子:
爆款内容的场景是白天,那就换成晚上;
爆款内容拍摄的是左手,那就换成右手……
用同样的变量替换一些变量,但是内容质量等不变,算法可理解,用户依然有触动。
但是并不是所有爆款内容模仿、复刻之后,依然是爆款,因为有些内容之所以成为爆款,可能是运气之类,因此并不是所有爆款内容都值得去模仿、复刻,值得去模仿、复刻的爆款内容一般是经过反复验证的、已经形成一定爆款内容模型/范本的。
综上,怎么发现值得去模仿、复刻的爆款内容呢?
思路 1. 查看品类下的商业报备笔记
假设有品牌商家已经摸索出自己的爆文模型的话,TA 们大概率会通过效果广告进行放大,所以可使用小红书数据分析工具,去查看自己品类下这段时间新增的商业报备笔记,找找看有没有适合自己的测试内容。
思路 2. 查看竞品的笔记
逻辑跟“思路 1. 商业报备”是一样的,所以可不定期使用小红书数据分析工具,去查看竞品这段时间新增的笔记内容,不一定需要局限于商业报备笔记,找找看有没有适合自己的测试内容。
思路 3. 小红书 App 浏览与搜索
小红书 App 的发现页是基于用户交互行为等的个性化推荐,所以可优先级多搜索自己品类/产品相关的内容,然后再多浏览与刷新几次发现页,在看到有类似的爆款内容重复多次出现在自己的发现页的时候,就可针对这个内容去搜索品牌/产品/标题等进行验证。
3. 人性洞察
爆款内容是可永恒的,小红书上出现的爆款内容,可能在其他渠道之前就已经出现过。
爆款内容的内核是对于人性的洞察,而人性大概率是不会发生改变的,唯一改变的是对于人性的阐述,以及表现方式。
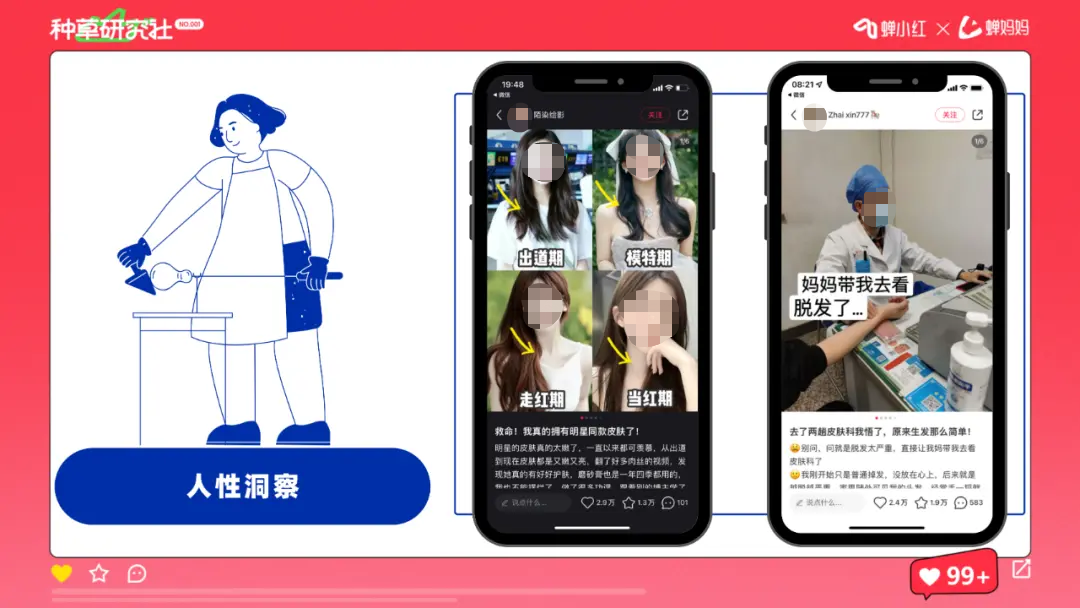
明星与医院,天然有可信度;
蓝手套、药单子,哪怕是假的,用户依然会觉得是有可信度。
4. 写在最后
1)内容选题 > 封面 > 标题 > 内容;
2)爆款内容创作需要迎合受众,而非引领受众;
因为迎合受众 = 迎合人性,而引领受众 = 反人性,难而正确。
三、爆款内容价值的极致化利用
所有的爆款内容得之不易,所以需要把爆款内容的价值进行极致化利用。
1. 基于爆款内容进行延伸与再利用


找到爆款因素,基于此出系列内容,e.g.
- 爆款因素是产品,内容成为爆款之后,同步测评同款不同型号的产品;
- 爆款因素是自己的蜕变,内容成为爆款之后,同步更新自己是如何蜕变的;
- 爆款因素是产品,内容成为爆款之后,同步更新产品的细节;
- ……
利用爆款内容博眼球,e.g.
- 用爆款内容截图作封面;
- 爆款内容的评论区截图作封面;
- ……
反复重复爆款内容,e.g.
- 忍不住再发一遍;
- 非商业报备发完、商业报备发、专业号转载发;
- xx 人看过的 xx;
- ……
2. 基于爆款内容进行复刻、创新
跟上述阐述的“用确定性蒙骗算法”差不多,即找到爆款因素,基于此进行复刻,甚至是创新,然后通过博主种草与效果广告投放进行放大,e.g. 爆款因素是 蓝手套 + 真实痛点 + 真实场景,基于此进行复刻、创新即可。
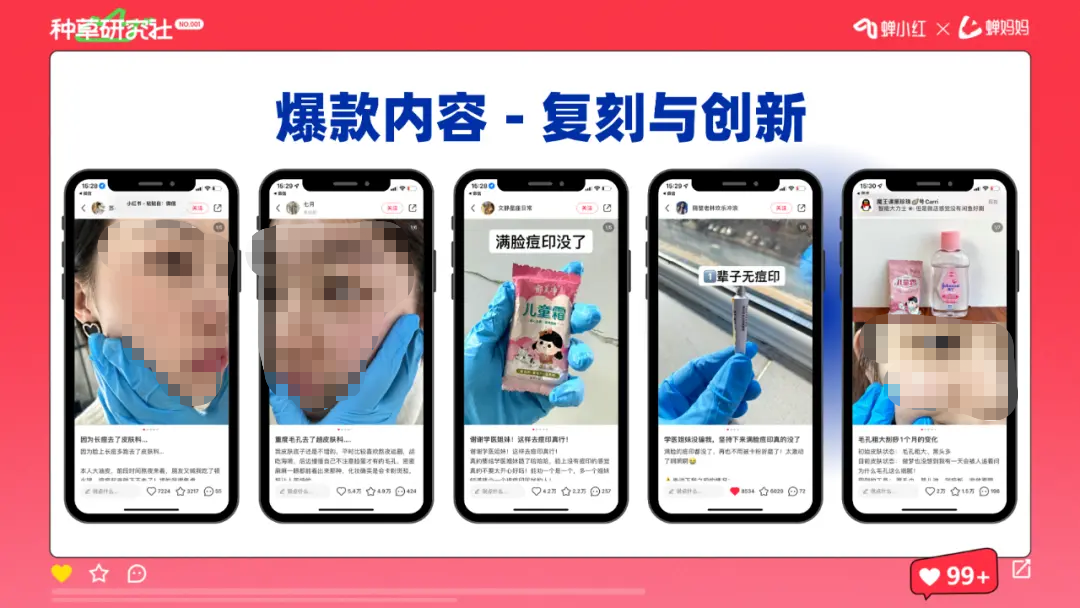
当然有些内容是没办法进行复刻、创新的。
3. 写在最后
让有效的爆款内容在渠道里流动,被看见、被放大。
分享一个超好用的短网址平台缩我短网址服务平台(短链接-免费长网址在线生成短网址缩短服务)可以把很长的网址缩短,而且还能监控网站的实时访问量。不仅所有的功能免费,而且功能还是我见过最多的,这也就是短网址界的天花板了吧。
功能:
1.网站缩短,永久有效,不限次数。支持动态替换背后的长链接。
2.API接口,简单易用、稳定可靠。
3.详细的访问数据统计,精准营销。包括点击量统计,来源地区、设备、浏览器,访问明细信息等等。
缩我(suowo.cn),老牌网址缩短、网址压缩、短网址、短链接工具,永久支持免费!平台功能全,短域名防封效果好,全网连通,跳转速度快,长期稳定,有效提升微信/QQ推广、其他社群推广、短信推广和其他互联网推广的效果

文章来源于网络,如有侵权,请联系客服删除处理。